
Two Models, Two Days, One Ceiling
Two frontier models. Forty-eight hours. One fascinating pattern emerging from the noise.

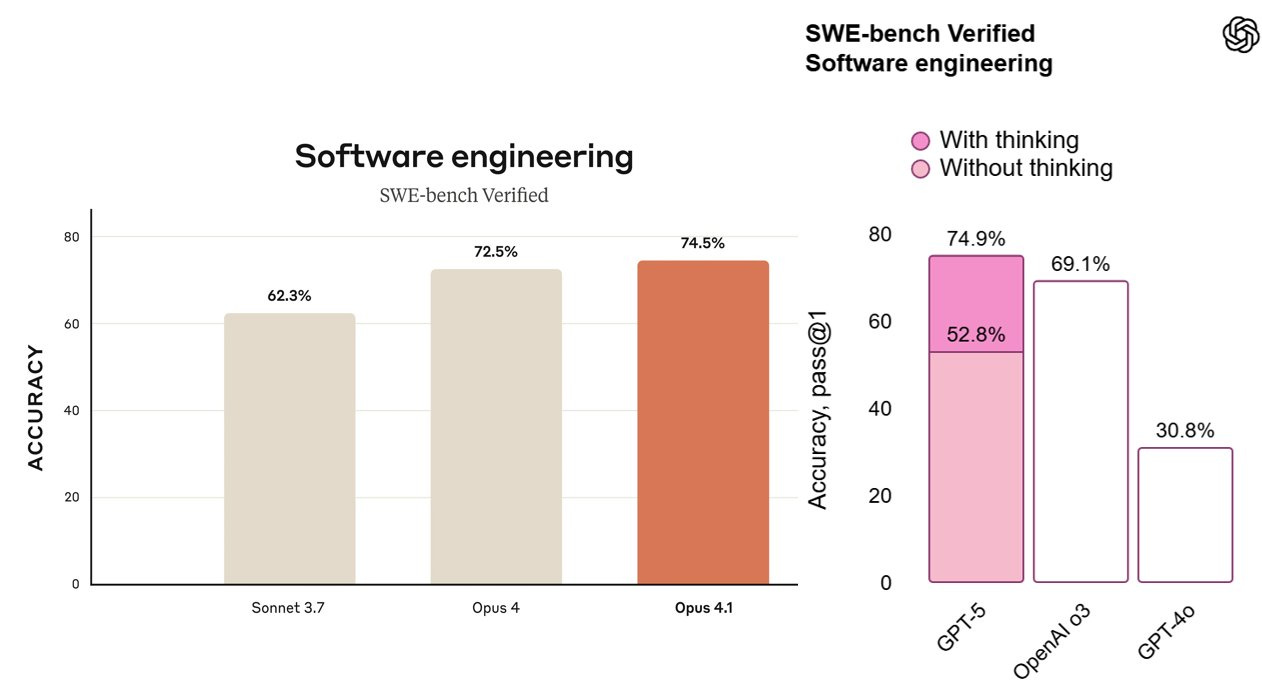
On August 5th, Anthropic released Claude Opus 4.1, achieving 74.5% accuracy on SWE-bench Verified. Two days later, OpenAI announced GPT-5, scoring 74.9% on the same benchmark. The timing raises questions, but the real story lies in what these near-identical scores tell us about where AI development stands today.
Think of it this way: after billions in compute and months of training, two independent teams reached essentially the same point. That's not a coincidence—it's a signal.
The Numbers Tell a Story
Let's examine what actually shipped in those 48 hours.
Both models cluster around that 74–75% mark on SWE-bench Verified, an industry-standard benchmark that measures a model’s ability to understand and fix real-world software issues by editing code repositories. Scores in the mid-70s represent a high bar—just 18 months ago, even top models were landing in the low 60s.
GPT-5 edges ahead by 0.4%. In statistical terms, that's essentially a tie. It's as if two Formula 1 teams, working independently with different philosophies, crossed the finish line within milliseconds of each other.
The fact that both teams landed here, independently, suggests we may be nearing the performance ceiling of current architectures on this type of coding challenge. Incremental scaling and fine-tuning alone might not deliver big gains from here; breaking past ~75% may require fresh data pipelines, novel architectures, or entirely new training paradigms.
But the architectural decisions reveal divergent strategies. OpenAI's GPT-5 isn't a single model—it's a system. A router evaluates each query and directs it to the appropriate model: a fast responder for simple tasks, a reasoning model for complex problems, and mini versions when compute limits are reached. It's sophisticated orchestration.
Anthropic took a different path with Opus 4.1. One model, consistent performance, no routing complexity. Both approaches have merit—OpenAI optimizes for flexibility and scale, while Anthropic prioritizes consistency and predictability.
Here's where it gets interesting: they're both right. The convergence on similar benchmarks suggests we're approaching what current architectures can achieve, but the divergence in implementation shows there's still room for innovation in how we deploy these capabilities.
The Distribution Chess Match
The strategic positioning reveals as much as the technology itself.
OpenAI made GPT-5 available to all ChatGPT users—including free tier. That's 700 million weekly active users getting frontier model access at no cost. Microsoft simultaneously integrated GPT-5 across GitHub Copilot, Visual Studio Code, M365 Copilot, and Azure. The infrastructure was ready on day one.
Anthropic maintains a more traditional approach: Opus 4.1 remains available to paid Claude users, through Claude Code, and via API. The focus appears to be on serving developers and enterprises who need reliable, consistent performance rather than reaching maximum distribution.
The pricing dynamics are particularly noteworthy. TechCrunch reports that GPT-5's pricing is "aggressively competitive," with developers praising the cost-to-capability ratio.
GPT-5’s rates are “aggressively competitive,” with developers praising the cost-to-capability ratio. In just two years, access to this level of capability has dropped from thousands annually to effectively free for millions. This isn’t just market-share play—it pressures rivals to match pricing, take margin hits, or focus on premium niches. Anthropic may respond by leaning into reliability, tooling, and enterprise trust rather than cutting prices.
Technical Realities Worth Noting
Both companies report significant improvements in hallucination reduction. OpenAI states GPT-5 shows "~45% fewer errors than GPT-4o" with web search enabled. The reasoning capabilities are particularly interesting: GPT-5's thinking mode reportedly achieves similar or better results than o3 while using 50-80% fewer tokens—a meaningful efficiency gain.
The infrastructure requirements paint a picture of the scale involved. OpenAI trained GPT-5 on Microsoft Azure using NVIDIA's H200 GPUs. The company reportedly has a $30 billion annual contract with Oracle for capacity. Meta plans to spend $72 billion on AI infrastructure in 2025. These numbers suggest we're entering a phase where computational resources become as important as algorithmic advances.
Perhaps most telling is what both companies emphasize: real-world utility over benchmark supremacy. GitHub reports that Opus 4.1 shows "notable performance gains in multi-file code refactoring." Cursor calls GPT-5 "remarkably intelligent, easy to steer." These qualitative assessments from actual users might matter more than fractional benchmark improvements.
Three Observations Worth Considering
First, the 75% ceiling on coding benchmarks appears significant.
Multiple models from different companies converging on similar scores suggests we might be approaching the limits of current training paradigms. This doesn't mean progress stops—it means the next jumps might require fundamental innovations rather than incremental scaling.
Second, architectural complexity versus simplicity represents a genuine trade-off.
GPT-5's multi-model system offers flexibility but introduces routing decisions and potential failure points. Claude's unified approach provides consistency but might sacrifice specialized performance. There's no clear winner—just different philosophies suited to different use cases.
Third, the democratization of frontier AI accelerates everything.
When capabilities that cost thousands of dollars annually two years ago become free, entire industries shift. We're watching the transition from AI as a premium service to AI as a utility. The implications ripple far beyond the technology sector.
The Path Forward
The next six months promise interesting developments. Anthropic will likely respond to OpenAI's pricing strategy, though probably not through direct price matching. Google's DeepMind and Meta have been relatively quiet—expect that to change. The infrastructure arms race intensifies as companies realize that model quality alone no longer provides sustainable differentiation.
Here's the profound shift: we're witnessing AI's transition from experimental technology to infrastructure. When multiple companies can achieve similar benchmark scores, when "state-of-the-art" differs by fractions of a percent, competition shifts to deployment, integration, and reliability.
The commoditization isn't a bug—it's a feature. Predictable, reliable AI that works consistently enables entirely new categories of applications. The interesting innovations might not come from the model makers but from those building on top of these increasingly stable foundations.
The Reality Check
What actually happened in those 48 hours deserves clear-eyed assessment. Two companies, working independently, achieved remarkably similar results. That's validation that the technology is maturing into something dependable.
GPT-5's efficiency gains are substantial. Claude's precision improvements matter for production use cases. The free tier access could unlock innovations we haven't imagined. These aren't revolutionary leaps, but they're solid steps forward in making AI more accessible and practical.
Consider the trajectory: About three years ago, ChatGPT had just launched. Claude wasn't publicly available. Today, we're debating whether 74.5% or 74.9% accuracy represents the frontier, while millions access these capabilities for free.
The 48-hour window between these releases revealed something important: we're in the optimization and deployment phase now. The models work. They're reliable enough for production. They're accessible enough for experimentation. The surprising truth? This stability might enable more transformative change than another breakthrough would.
Keep a lookout for the next edition of AI Uncovered!
Follow our social channels for more AI-related content: LinkedIn; Twitter (X); Bluesky; Threads; and Instagram.