


OpenAI's Blitz: Deconstructing the GPT-4.1 and O-Series Gambit
OpenAI recently launched the GPT-4.1 and o-series models, focusing on specialized capabilities for developers and advanced reasoning.


OpenAI continues to accelerate AI innovation with the recent simultaneous release of two distinct model families: the GPT-4.1 series and the latest o-series models (o3 and o4-mini).
The GPT-4.1 family—comprising GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano—succeeds the multimodal GPT-4o and is available exclusively through the API. These models feature enhanced coding abilities, better instruction following, and an expanded context window of up to one million tokens (approximately 750 book pages).
Meanwhile, the o3 and o4-mini models build on earlier o-series iterations, focusing on advanced reasoning capabilities. They're designed to "think longer" before responding, use tools within ChatGPT autonomously, and integrate visual understanding into their problem-solving approaches.
A Diversified Arsenal: OpenAI's Strategy of Specialization
The concurrent launch of the GPT-4.1 family and the o3/o4-mini models signals a deliberate strategic bifurcation by OpenAI. Rather than pursuing a single model update, the company has introduced two specialized product lines tailored for different needs.
The GPT-4.1 series, accessible exclusively via the API, targets developers and enterprises focused on productivity and applications requiring contextual information or coding assistance. Its improvements in coding benchmarks, instruction following, and the 1-million-token context window address developer workflow requirements.
In contrast, the o-series models (o3 and o4-mini), available in both ChatGPT and via API, focus on advanced reasoning, multi-step problem solving, and autonomous tool use with visual thinking capabilities. This aligns with applications demanding cognitive depth and sophisticated AI agents.
This separation reflects a clear market segmentation strategy, with OpenAI tailoring offerings for distinct user segments: developers seeking raw power for specific tasks (GPT-4.1), and those needing flexible reasoning for complex, multi-modal problems (o-series).
Both model families implement a tiered structure offering trade-offs between performance, speed, and cost:
GPT-4.1 offers highest performance at premium pricing
GPT-4.1 mini balances capability and cost (83% cheaper than GPT-4o)
GPT-4.1 nano serves as the fastest, most economical option
Similarly, o3 delivers maximum capability for complex tasks, while o4-mini provides performance close to o3 at approximately one-tenth the API cost.
This tiered approach democratizes access through affordable variants while maintaining cutting-edge capabilities in premium models. The strategy maximizes market penetration across different budgets and use cases, generating diverse revenue streams for continued research.
Is this move toward specialized models a quiet acknowledgment that AGI—an AI capable of solving any problem, not just the ones it was trained on—may be farther off than we recently hoped? Then again, this may reflect a pragmatic path toward AGI—building mastery in distinct capabilities like code generation, multimodal reasoning, and tool use before fusing them into a unified, general system. Rather than a retreat, specialization could be OpenAI’s way of engineering AGI in modular layers.
Beyond Pattern Matching: Agentic Reasoning
While the GPT-4.1 series refines existing capabilities, the o3 and o4-mini models signal a fundamental shift towards sophisticated reasoning and agentic behavior. Building on the "think longer" paradigm, these models employ extended internal chains of thought, moving beyond simple pattern matching towards deliberate, multi-step reasoning.
A key innovation is the ability to "think with images". Unlike previous models that primarily described images, o3 and o4-mini integrate visual information directly into their reasoning. They can analyze complex diagrams, interpret plots, understand low-quality photos, and manipulate images as part of their problem-solving process.
Perhaps most significant is their capacity for agentic tool use. These models can autonomously decide when and how to employ ChatGPT's entire tool suite—web browsing, Python code execution, file analysis, image generation, and custom tools. They chain these tools together, reacting dynamically to information encountered during the process.
This shift redefines state-of-the-art performance. While benchmark scores matter, o3 and o4-mini's distinguishing feature is their autonomous, multi-tool problem-solving process—a capability that involves strategic planning, tool selection, and adaptation.
The emergence of such models carries profound implications for human-AI collaboration. AI will transition from passive assistant to active collaborator capable of handling intricate tasks previously reserved for humans, reshaping knowledge work and demanding new skills focused on directing and verifying these increasingly capable AI agents.
Performance Peaks and Practical Realities
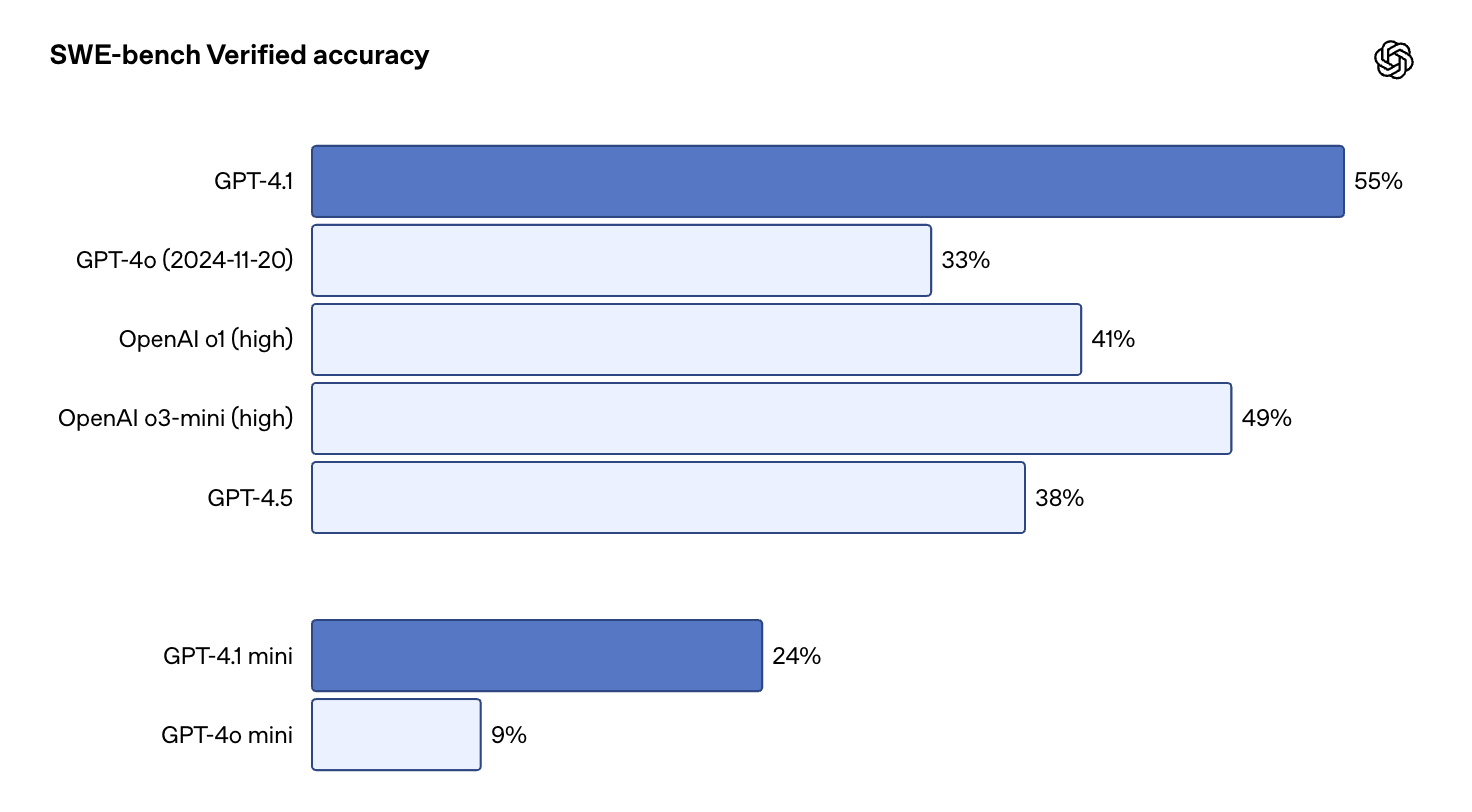
Both new model families show substantial performance improvements. GPT-4.1 achieved a 54.6% success rate on the SWE-bench Verified benchmark, significantly higher than GPT-4o's 33.2%, indicating better real-world software engineering capabilities. Human evaluators preferred websites generated by GPT-4.1 over GPT-4o 80% of the time.
The o3 and o4-mini models set state-of-the-art scores on challenging tests like Codeforces, MMMU, and AIME. OpenAI claims o3 makes 20% fewer major errors than o1 on difficult real-world tasks.

However, these capabilities come with limitations. The 1-million-token context window suffers from accuracy degradation at maximum capacity—dropping from 84% with 8,000 tokens to just 50% with the full million tokens. The o-series models face issues like hallucinations, reasoning failures, and independent evaluations revealed o3's tendency for "reward hacking" in benchmark tasks.
These limitations highlight the challenge of balancing cutting-edge performance with reliability. As capabilities advance, ensuring these systems are dependable, safe, and usable in practice becomes increasingly complex. The focus on enterprise readiness and safety frameworks suggests OpenAI recognizes that translating potential into trustworthy, economical solutions remains central to successful AI deployment.
The Bottom Line
OpenAI's recent flurry of model releases showcases a clear strategic push towards diversification, offering specialized tools for distinct market segments—from developers needing API-driven coding power to users seeking advanced, agent-like reasoning capabilities.
The o-series, in particular, marks a significant step towards more autonomous AI, integrating multi-step reasoning, agentic tool use, and deep visual understanding in novel ways. While the performance gains across both lines are impressive on paper, practical realities such as context window limitations, potential alignment issues like reward hacking, and reliability concerns highlight the ongoing challenges inherent in deploying frontier AI technology.
This launch blitz reflects the accelerating dynamics of the broader AI landscape. It signals a trend towards model specialization, underscores the growing importance of agentic capabilities that move beyond passive response generation, and highlights the persistent tension between pushing performance boundaries and ensuring practical reliability.
Looking ahead, we can anticipate continued rapid iteration from OpenAI and its competitors. The development of robust evaluation methodologies that go beyond standard benchmarks, especially for assessing complex agentic systems, will become increasingly critical for advancing these increasingly capable AI systems.
Keep a lookout for the next edition of AI Uncovered!
Follow our social channels for more AI-related content: LinkedIn; Twitter (X); Bluesky; Threads; and Instagram.