
LLM Comparative Analysis: Key Metrics for the Top 5 LLMs
A comparative analysis of the top LLMs: GPT-4 by OpenAI, Claude 3 by Anthropic, Llama 3 by Meta, Mistral Large by Mistral AI, and Grok-1 by xAI.


Large language models (LLMs) have undoubtedly emerged as a game-changing technology. These AI models, trained on vast amounts of data, have the ability to understand, generate, and manipulate human language with unprecedented accuracy and fluency. Among the numerous LLMs developed by various organizations, a few models have particularly stood out for their exceptional performance and potential: GPT-4 by OpenAI, Claude 3 by Anthropic, Llama 3 by Meta, Mistral Large by Mistral AI, and Grok-1 by xAI.
GPT-4, the successor to the renowned GPT-3.5 that powered ChatGPT, has demonstrated remarkable capabilities across a wide range of tasks, from answering questions to generating creative content. Claude 3, with its focus on "constitutional AI," aims to create AI systems that align with predefined principles and values. Llama 3, Meta's open-source LLM, has shown impressive performance on various natural language processing tasks while supporting multiple languages. Mistral Large, developed by French AI company Mistral AI, boasts top-tier reasoning capabilities and native fluency in several languages. Finally, Grok-1 leverages a Mixture-of-Experts architecture to achieve high accuracy and efficiency.
As these five LLMs push the boundaries of what is possible with AI language technologies, it becomes increasingly important to understand their unique strengths, limitations, and potential applications. This comparative analysis aims to provide a comprehensive overview of how they stand out in terms of accuracy, speed, model size, energy efficiency, and cost.
But how are these models evaluated and compared? What are the benchmarks that allow us to assess their capabilities? To gauge the effectiveness of LLMs, researchers rely on a variety of benchmarks, each designed to test different aspects of the model's performance. These include language understanding, language generation, specialized tasks, efficiency and scalability, and fairness and bias.
By utilizing these benchmarks, researchers and developers can provide a comprehensive evaluation of LLMs, ensuring they meet the standards required for practical applications and contribute positively to advancements in AI technologies.
Let’s review these metrics in more detail.
Metrics Key:
To evaluate the accuracy of these LLMs, researchers and developers rely on various benchmarks and standardized tests. These include:
MMLU (Massive Multitask Language Understanding): A benchmark that assesses an LLM's ability to understand and reason about a wide range of topics and domains.
HellaSwag: A test that measures an LLM's common sense reasoning and ability to complete sentences based on contextual understanding.
Wino Grande: A benchmark that evaluates an LLM's capacity for pronoun resolution and coreference reasoning.
ARC (AI2 Reasoning Challenge): A question-answering dataset that tests an LLM's ability to reason about complex scientific and technical concepts.
TriviaQA: A benchmark that assesses an LLM's performance in answering trivia-style questions across various domains.
By examining these key metrics, we can gain valuable insights into the current state of LLM development and make informed decisions when choosing the most suitable model for specific use cases.
For those interested in diving even deeper, you will find various resources for further reading at the end of this piece.
Accuracy
Accuracy is one of the most critical factors in evaluating the performance of LLMs. It refers to the model's ability to generate output that is correct, relevant, and coherent with respect to the given input or task. A highly accurate LLM can better understand and respond to user queries, produce high-quality content, and perform well on a wide range of natural language processing (NLP) tasks, such as text classification, sentiment analysis, and question answering.
When comparing the accuracy of the top five LLMs, we can observe some notable differences and similarities. GPT-4 and Claude 3 Opus have consistently demonstrated leading accuracy across various benchmarks, such as MMLU, HellaSwag, and Wino Grande. These models have shown remarkable performance in understanding and generating human-like text, as well as in tasks that require common sense reasoning and knowledge extraction.
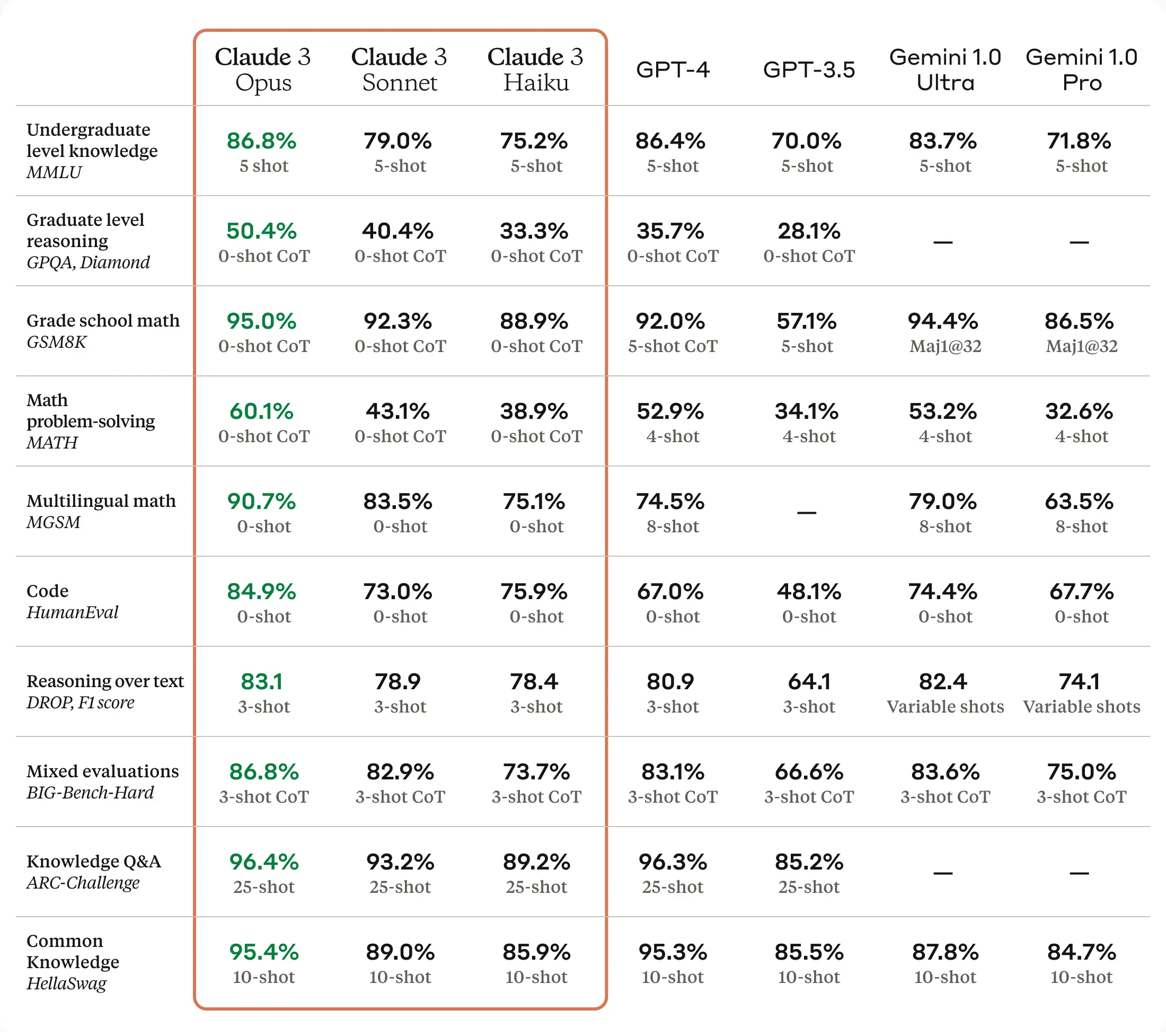
Mistral Large, while trailing slightly behind GPT-4 and Claude 3 Opus, has exhibited strong reasoning capabilities. It has achieved impressive results on benchmarks like MMLU, ARC, and TriviaQA, outperforming models like Llama 2 and GPT-3.5. This highlights Mistral Large's ability to effectively process and analyze complex information and provide accurate responses to challenging queries.
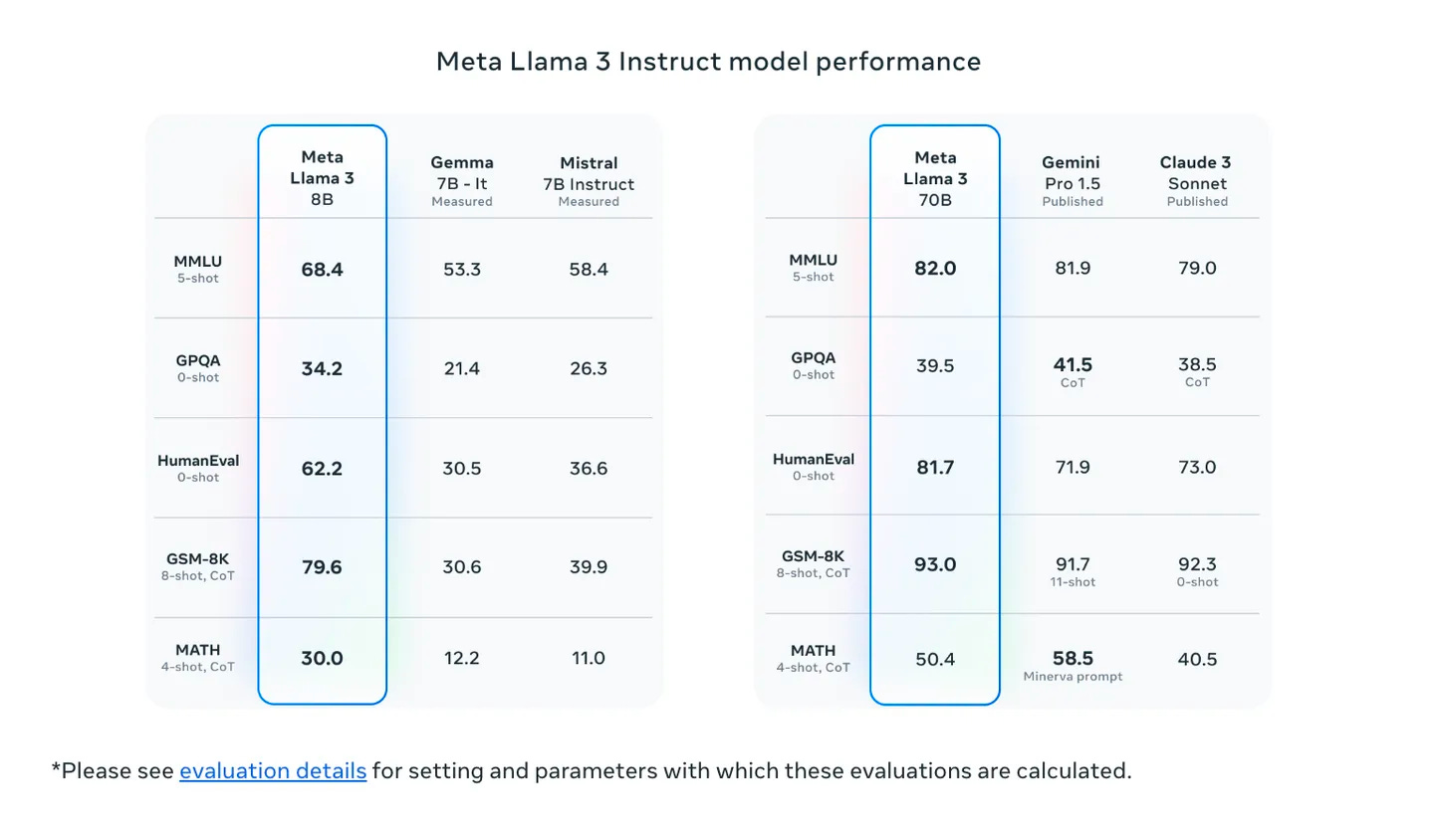
Llama 3, particularly its 70B version, has shown significant improvements over its predecessor, Llama 2. It has solidly outperformed models like Grok-1 on benchmarks such as HumanEval and GSM-8K, demonstrating its enhanced accuracy in code generation and mathematical reasoning tasks. Even the smaller 8B version of Llama 3 has managed to surpass Grok-1 on nine benchmarks, showcasing its efficiency and accuracy in various NLP tasks.
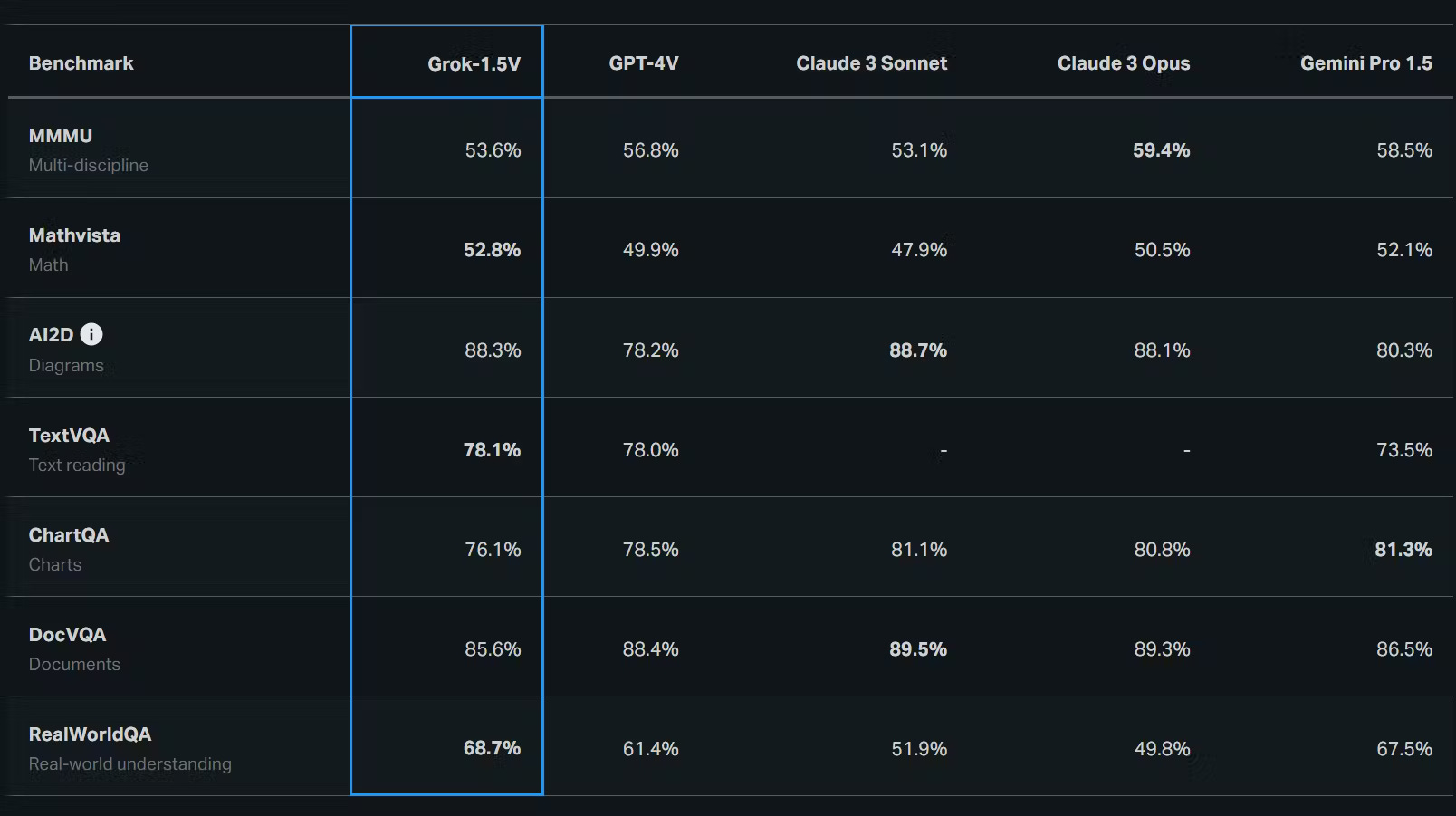
Grok-1, while trailing behind GPT-4, Claude 3 Opus, Mistral Large, and Llama 3 on most accuracy benchmarks, has shown promising improvements with its latest iteration, Grok-1.5. This updated model has demonstrated near-GPT-4 level performance on some tasks, indicating its potential to close the accuracy gap with further development and refinement.
Speed
In addition to accuracy, the speed at which large language models can process and generate text is a crucial factor in their usability and practicality. Inference speed, or the time it takes for an LLM to generate a response to a given input, directly impacts the user experience and the feasibility of deploying these models in real-world applications. A faster LLM can provide more responsive and seamless interactions, making it better suited for tasks that require quick turnaround times, such as chatbots, virtual assistants, and real-time language translation.
We can observe some notable differences in the models’ approaches to optimizing inference speed. Mistral models, for instance, have been specifically designed for low latency and fast inference. By employing techniques like GQA (Gated Query Attention) and SWA (Stochastic Weight Averaging), Mistral 7B, a smaller variant of Mistral Large, has achieved impressive speed while maintaining high accuracy.
Gated Query Attention (GQA): GQA is a technique used in LLMs to improve the efficiency of the attention mechanism. It introduces a gating function that learns to selectively attend to different parts of the input sequence based on the relevance to the current query. By focusing on the most important information, GQA reduces computational overhead and speeds up inference while maintaining high accuracy.
Stochastic Weight Averaging (SWA): SWA is an optimization technique that involves averaging the weights of multiple model checkpoints obtained during training. Instead of using the final model weights, SWA computes a running average of the weights at different points in the training process. This averaging helps to stabilize the model's performance, reduce overfitting, and improve generalization. Models trained with SWA often exhibit faster inference speeds and better accuracy compared to their non-SWA counterparts.
Llama 3, Meta's open-source LLM, has also demonstrated improved speed compared to its predecessor, Llama 2. The smaller 8B version of Llama 3 can run faster than the larger 70B model, making it a more efficient option for applications that require quick responses without compromising too much on accuracy.
Grok has taken a unique approach to optimize speed by designing custom hardware specifically for LLM workloads. This allows Grok to achieve higher throughput and faster inference compared to other models running on general-purpose hardware. As a result, Grok is more efficient than many other LLMs, enabling it to be trained and run on less powerful systems.
On the other hand, GPT-4 and Claude 3, particularly the larger Opus variant, prioritize accuracy over raw speed. These models have been designed to deliver state-of-the-art performance on a wide range of tasks, often at the expense of slower inference times. However, this trade-off is justified for applications where the quality and reliability of the generated text are of utmost importance, such as in content creation, language understanding, and complex reasoning tasks.
To improve inference speed, LLMs employ various techniques and optimizations. Some of these include:
Quantization: Reducing the precision of the model's weights and activations to speed up computations and reduce memory footprint.
Pruning: Removing less important weights and connections from the model to create a smaller, more efficient architecture.
Distillation: Training a smaller, faster student model to mimic the behavior of a larger, more accurate teacher model.
Hardware acceleration: Utilizing specialized hardware, such as GPUs, TPUs, or custom chips, to parallelize computations and speed up inference.
By comparing the speed of the top LLMs and understanding the techniques they employ to optimize inference times, developers and researchers can make informed decisions when selecting a model for their specific use case. For applications that require real-time responsiveness, models like Mistral and Llama 3 may be more suitable, while GPT-4 and Claude 3 may be preferred for tasks that prioritize accuracy over speed.
Model Size
Model size, which refers to the number of parameters in a LLM, is another essential factor to consider when comparing LLMs. The size of an LLM directly impacts its performance, as larger models can capture more complex patterns and nuances in the training data, leading to better accuracy and generalization. However, increasing model size also comes with trade-offs, such as higher computational requirements, longer training times, and increased energy consumption.

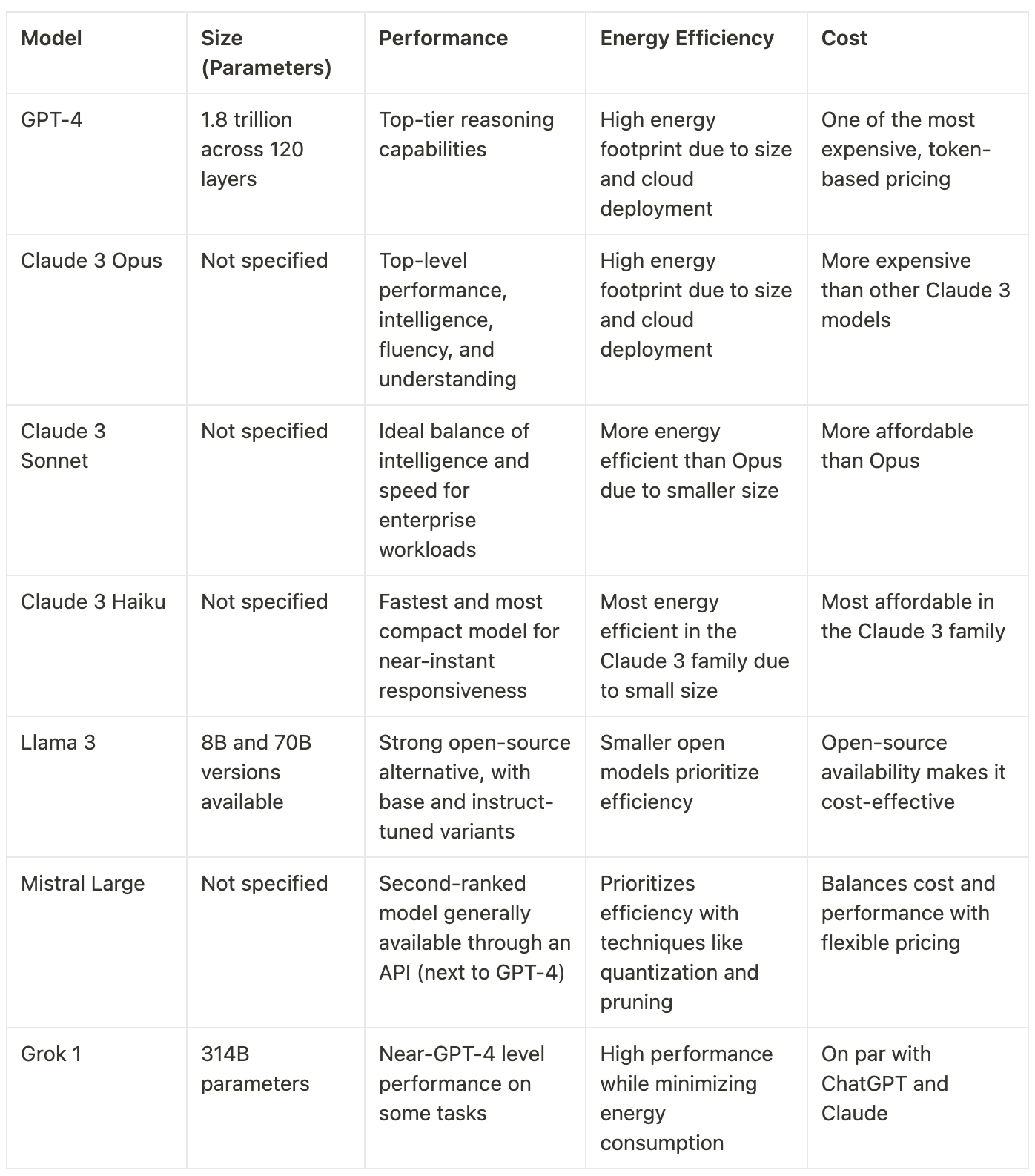
With the models we are looking at, we can observe a wide range of sizes, each with its own implications for performance and efficiency. GPT-4, developed by OpenAI, is estimated to have an extremely large size, potentially surpassing 170 billion parameters. While the exact number is not publicly disclosed, GPT-4's massive size contributes to its exceptional performance across a wide range of tasks.
Claude 3, created by Anthropic, comes in three different sizes: Haiku, Sonnet, and Opus. Opus, the largest variant, is designed to deliver high accuracy and competes closely with GPT-4 on various benchmarks. Sonnet and Haiku, the smaller versions, offer a balance between performance and efficiency, making them suitable for applications with more limited computational resources.
Llama 3, Meta's open-source LLM, is available in two sizes: 8 billion and 70 billion parameters. The 70B version has demonstrated solid performance, outperforming models like Grok-1 on benchmarks such as HumanEval and GSM-8K. The 8B version, while smaller, still manages to surpass Grok-1 on nine benchmarks, showcasing its efficiency and accuracy. Meta is also working on even larger Llama models, with sizes exceeding 400 billion parameters, which could further push the boundaries of LLM performance.
Mistral Large, developed by Mistral AI, is a high-capability model with a large context window of 32,000 tokens. While the exact number of parameters in Mistral Large is not public, its strong reasoning capabilities and native fluency in several languages suggest a substantial model size. Mistral AI also offers smaller, open-source models like Mistral 7B, which provide a more accessible option for developers and researchers.
Grok is one of the largest open models available, with 314 billion parameters. Its successor, Grok-1.5, builds upon this foundation, incorporating architectural improvements and additional training data to enhance performance. The massive size of Grok-1 and Grok-1.5 enables them to tackle complex tasks and achieve high accuracy, although they may require more computational resources compared to smaller models.
When considering model size, it is essential to understand the trade-offs between performance, efficiency, and cost. Larger models generally offer better accuracy but require more computational power, memory, and energy to train and run. Smaller models, on the other hand, may sacrifice some accuracy for improved efficiency and lower resource requirements. The choice of model size depends on the specific needs of the application, available resources, and the balance between accuracy and efficiency.
Energy Efficiency
As LLMs become increasingly powerful and complex, the energy consumption associated with their training and deployment has become a significant concern. Energy efficiency is crucial not only for reducing the environmental impact of LLMs but also for making them more accessible and cost-effective to use.
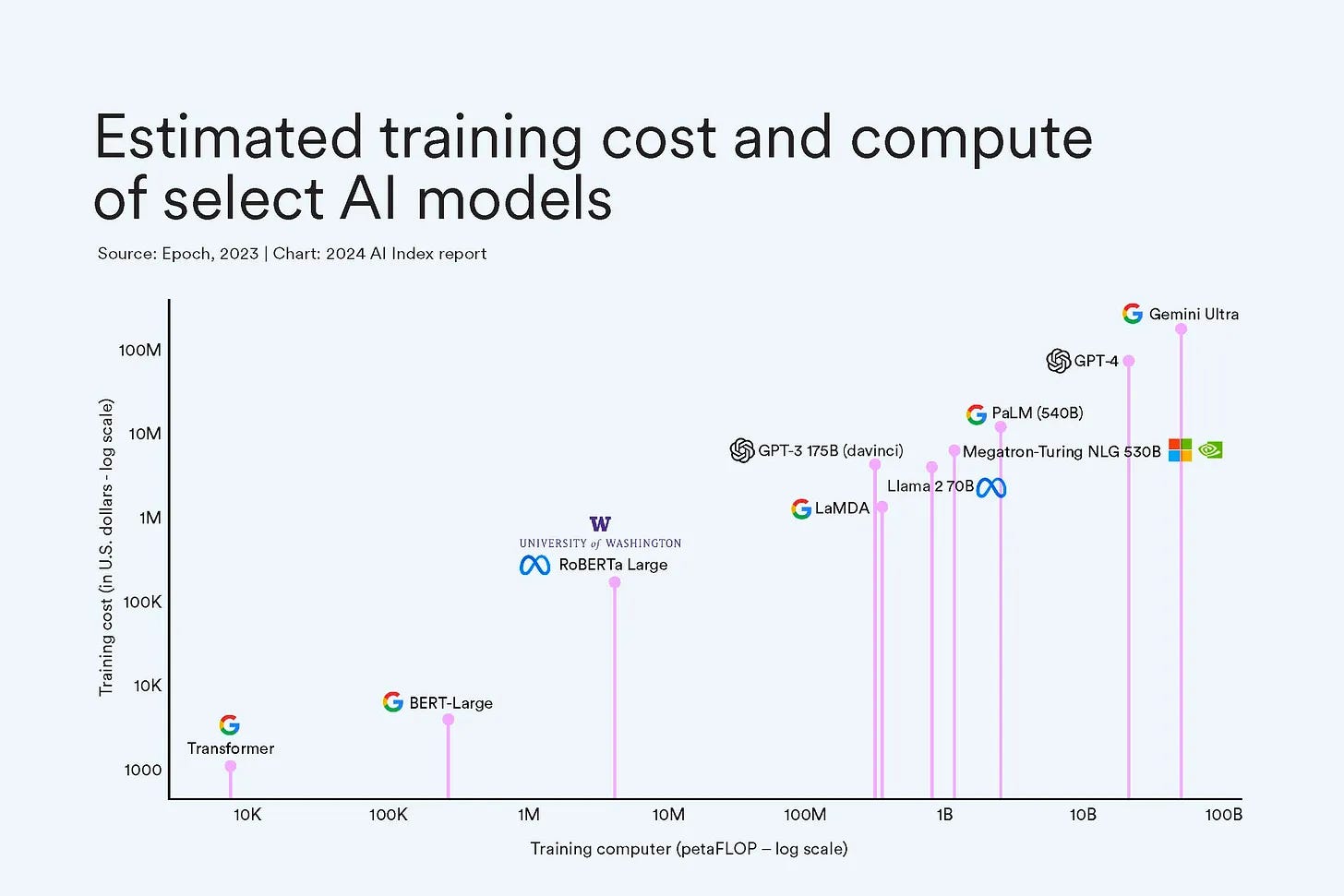
Mistral, developed by Mistral AI, places a strong emphasis on energy efficiency by utilizing smaller, open-source models that can run locally with fewer resources. By leveraging techniques like quantization and pruning, Mistral models can achieve high performance while reducing the energy required for inference. This approach makes Mistral an attractive option for applications that prioritize sustainability and low energy consumption.
Llama 3, Meta's open-source LLM, also demonstrates a focus on energy efficiency, particularly with its smaller 8B version. Compared to the larger 70B model, which requires significant computational resources, the 8B version of Llama 3 can achieve impressive performance while consuming less energy. This makes it a more sustainable choice for applications that do not require the full capabilities of the larger model.
Grok takes a unique approach to energy efficiency by designing custom hardware optimized specifically for LLM workloads. By leveraging specialized chips and architectures, Grok can achieve high performance while minimizing energy consumption compared to models running on general-purpose hardware. This hardware-software co-design strategy allows Grok to be more efficient than many other LLMs, reducing its environmental footprint.
On the other hand, large models like GPT-4 and Claude 3 Opus, which prioritize accuracy and performance, may consume higher amounts of energy due to their massive sizes and the computational resources required to run them. As these models are often deployed in cloud environments, the energy consumption associated with their use can be substantial. However, it is essential to note that the exact energy consumption of these models is not always publicly disclosed, making it challenging to make direct comparisons.
Models like Mistral and Llama 3, which prioritize efficiency and sustainability, may be preferred for applications that aim to minimize their carbon footprint, while GPT-4 and Claude 3 Opus may be chosen for tasks that require the highest levels of accuracy and performance, despite their potentially higher energy consumption.
Cost for End Users
The cost of using LLMs, in terms of the price for end users rather than model training costs, is a significant factor in their adoption and accessibility. As LLMs become more powerful and complex, the associated costs can vary greatly.
GPT-4 is one of the most expensive LLMs, with a pricing model based on the number of tokens processed. For the API, users are charged $0.03 per 1,000 input tokens and $0.06 per 1,000 output tokens, which can quickly add up for applications that require extensive text generation or processing. In terms of ChatGPT, the widely used online interface, users can access GPT-4 for $20/month. While GPT-4's high accuracy and performance may justify its cost for some use cases, its pricing can be a barrier for smaller businesses or individuals with limited budgets.
Claude 3 offers a more affordable alternative to GPT-4, particularly with its Haiku and Sonnet versions. Claude 3 Haiku charges $0.25 per 1 million input tokens and $1.25 per 1 million output tokens, making it 120 times cheaper than GPT-4's 8K model for prompt tokens and 48 times cheaper for output tokens. Similarly, Claude 3 Sonnet is priced at $3 per 1 million input tokens and $15 per 1 million output tokens, making it 10 times cheaper for prompt tokens and 4 times cheaper for output tokens compared to GPT-4's 8K model. Even the largest version, Claude 3 Opus, offers a more cost-effective solution than GPT-4 while still delivering comparable accuracy and performance, with pricing being $15 per 1 million input tokens and $75 per 1 million output tokens. The Claude web-based chatbot, which offers all three models, costs $20 per month, similar to ChatGPT.
Llama 3, Meta's open-source LLM, stands out for its cost-effectiveness and accessibility. Both the 8B and 70B versions of Llama 3 are available for free, making them an attractive option for researchers, developers, and businesses looking to experiment with and deploy LLMs without significant upfront costs. The open-source nature of Llama 3 also allows for customization and fine-tuning, enabling users to adapt the model to their specific needs without incurring additional licensing fees.
Mistral Large, developed by Mistral AI, offers a balance between cost and performance. The company provides both open-source and commercial models, with the open-source versions, like Mistral 7B, being free to use. The commercial models, such as Mistral Large, are priced competitively, making them accessible to a wide range of users. Mistral Large is priced at $8 per 1 million input tokens and $24 per 1 million output tokens. Mistral's focus on energy efficiency and the ability to run models locally further contributes to its cost-effectiveness, as users can save on cloud computing expenses.
Grok is currently available only to X Premium+ subscribers at a monthly fee of $16. While this pricing model may be more expensive compared to free options like Llama 3 or ChatGPT, it is on par with other paid services like ChatGPT Plus. However, the cost of using Grok should be weighed against its performance and the specific requirements of the application.
When evaluating the cost-to-performance ratio of the top LLMs, models like Claude 3 Haiku/Sonnet and Mistral Large stand out for their ability to deliver strong performance at a lower cost compared to GPT-4. Llama 3's open-source availability makes it an excellent choice for cost-sensitive applications, while Grok-1's pricing may be justified for users who require its specific capabilities and are willing to pay for the X Premium+ subscription.
Final Thoughts on the Top LLMs
In this comparative analysis, we have examined some of the top LLMs across five key metrics: accuracy, speed, model size, energy efficiency, and cost. By evaluating these LLMs along these dimensions, we have gained valuable insights into their strengths, weaknesses, and potential applications.
In terms of accuracy, GPT-4 and Claude 3 Opus consistently lead the pack, with Mistral Large following closely behind. Llama 3 has shown impressive performance, outperforming Grok-1 on several benchmarks, while the upcoming Grok-1.5 shows promise in closing the accuracy gap with the top models.
When considering speed, models like Mistral and Llama 3 have demonstrated excellent efficiency, with optimized architectures and techniques like GQA and SWA contributing to their fast inference times. Grok's custom hardware design also enables high throughput and reduced latency, making it a strong contender in terms of speed.
Model size plays a crucial role in determining the performance and efficiency of LLMs. GPT-4 and Claude 3 Opus boast massive sizes, enabling them to tackle complex tasks with high accuracy. Llama 3 and Mistral Large offer a range of sizes, catering to different performance and resource requirements. Grok-1 and its successor, Grok-1.5, stand out as some of the largest open models available, showcasing the potential of open-source LLMs.
Energy efficiency has become an increasingly important consideration in the development and deployment of LLMs. Models like Mistral and Llama 3 prioritize efficiency, with smaller open models and techniques like quantization and pruning helping to reduce energy consumption. Grok's custom hardware optimization also contributes to its energy efficiency, while large models like GPT-4 and Claude 3 Opus may have higher energy footprints due to their size and cloud deployment.
Finally, the cost of using LLMs varies significantly among the top five models. GPT-4 stands out as one of the most expensive, with a token-based pricing model that can quickly accumulate costs. Claude 3 Haiku and Sonnet offer more affordable alternatives, while Llama 3's open-source availability makes it an attractive choice for cost-sensitive applications. Mistral Large and Grok provide a balance between cost and performance, with pricing models that cater to different user needs.
As the field of LLMs continues to evolve, the competition among these top models is expected to intensify. Each model's unique strengths and value propositions will drive innovation and shape the future of AI-powered applications. Developers, researchers, and businesses must carefully consider their specific requirements in terms of accuracy, speed, model size, energy efficiency, and cost when selecting an LLM for their use case.
Further Reading on LLMs for the Technically Inclined
A Survey on Evaluation of Large Language Models - This paper provides a comprehensive overview of various approaches and methodologies used to evaluate LLMs across different applications and domains. Read the survey here
A Comprehensive Overview of Large Language Models - This paper discusses the mechanisms of LLMs, including tokenization, encoding, and attention mechanisms, which are essential for understanding how these models are built and evaluated. Explore the overview here
Large Language Models: A Survey - This survey covers the broad landscape of LLM development, focusing on model architectures, training methods, and performance benchmarks, providing a solid foundation for understanding the current state of LLM technologies. Read the survey here
Evaluating Large Language Models (LLMs) with Eleuther AI - This online resource provides tools and methodologies for conducting practical evaluations of LLMs, offering insights into their capabilities and limitations. Check out the evaluation methods here
Leveraging Large Language Models for NLG Evaluation: A Survey - This paper reviews the use of LLMs in natural language generation (NLG) evaluation, detailing various evaluation strategies and their effectiveness. Read more about NLG evaluation here
Evaluating Large Language Models at Evaluating Instruction Following (2023) - This research explores the use of large language models in evaluating their ability to follow instructions, highlighting a new approach to measuring model efficacy through adversarial testing. Explore the study
Self-contradictory Hallucinations of Large Language Models: Evaluation, Detection, and Mitigation (2023): This paper provides a comprehensive analysis of self-contradictory hallucinations in large language models, discussing methods for their evaluation, detection, and mitigation. The study focuses on various instruction-tuned LLMs, and offers insights into the complexities of managing these inconsistencies in generated text. You can explore this paper in detail here.
VALOR-EVAL: Holistic Coverage and Faithfulness Evaluation of Large Vision-Language Models (2024) - This paper introduces a new benchmark for evaluating the holistic coverage and faithfulness of large vision-language models, which could be extrapolated to textual models for comprehensive assessments. Read about VALOR-EVAL
Keep a lookout for the next edition of AI Uncovered, which will cover the challenges associated with developing and testing metrics for LLMs.
Follow on Twitter, LinkedIn, and Instagram for more AI-related content!