


DeepSeek and the Efficiency Paradigm
Examining the architectural innovations and market implications of DeepSeek.


DeepSeek, a Chinese AI startup that emerged in July 2023, has established itself as an unexpected force. The company's recent release of LLMs - particularly its flagship models DeepSeek V3 and R1 - has attracted exceptional attention for challenging established assumptions about AI development costs and computational requirements.
DeepSeek V3 is an ambitious entry into the competitive AI market, introducing a 671-billion-parameter model built on the mixture-of-experts (MoE) architecture - a sophisticated approach to neural network design. Unlike traditional models that use all their parameters for every computation, MoE systems work like a specialized team of experts, each trained for specific types of tasks.
What makes DeepSeek V3 particularly notable is its selective activation system: for any given token (a piece of text or data being processed), it activates only 37 billion parameters out of the total 671 billion. This selective engagement allows the model to maintain high performance while dramatically reducing computational overhead.
This architectural choice reflects a fundamental shift in how large language models can be designed. By activating only the most relevant "expert" parameters for each specific task, DeepSeek claims to achieve the capabilities of much larger models while using a fraction of the computing resources. Meanwhile, its companion model R1 focuses on reasoning capabilities, applying this efficient architecture to complex mathematical, logical, and coding challenges. Early benchmarks suggest R1's performance matches industry leaders, though these claims have drawn both interest and skepticism from the technical community.
From my personal perspective, I fully agree with Reid Hoffman’s insights on DeepSeek. It certainly doesn’t spell the end of hyperscalers—rather, it highlights the ongoing need for large-scale models. After all, DeepSeek likely leveraged bigger models (like ChatGPT) to develop its own capabilities. As Reid points out, this development underlines how small AI companies, both in China and in the U.S., are successfully using large models to train or refine their own innovations. And while DeepSeek showcases China’s impressive AI talent and rapid pace of advancement, it’s also a reminder for Silicon Valley and beyond to keep investing in and evolving the next generation of powerful AI models.
It is also very likely, as many have pointed out, that DeepSeek was built by “distilling” other models, such as Llama, and used black-market NVIDIA chips. Regardless, this does represent a “Sputnik moment” as it has been described, marking a historical pivot point, reminiscent of the 1957 Sputnik launch that sparked the global space race, driving intense competition and massive investment. From a technical standpoint, this “Sputnik moment” signals how a single breakthrough—like DeepSeek—can catalyze a surge in innovation, prompting both established hyperscalers and emerging startups to push the boundaries of AI research and deployment in a bid to stay ahead.
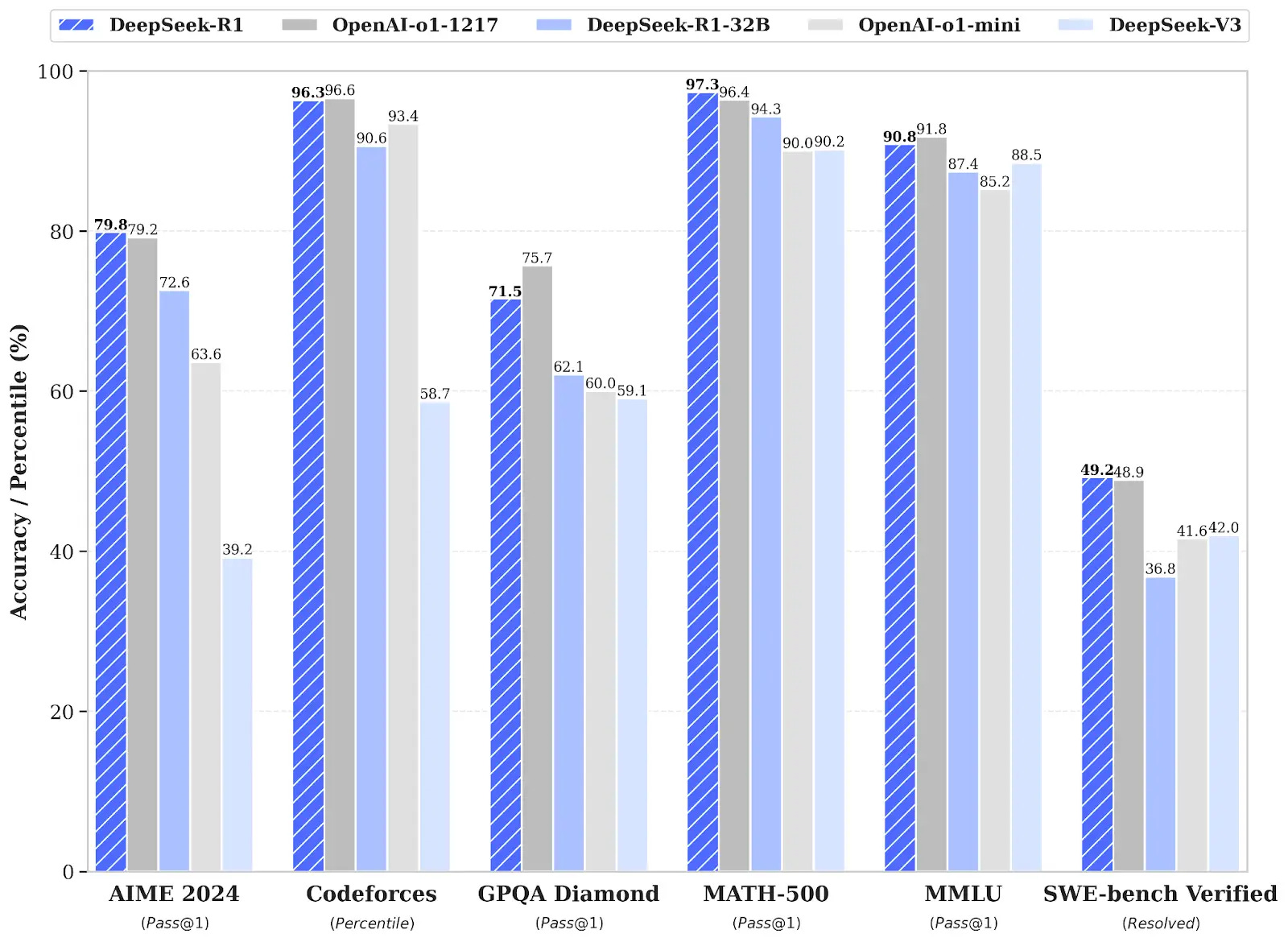
The company's emergence has proven particularly notable for two key claims: first, that it achieved these capabilities at a fraction of established development costs, and second, that it requires significantly fewer computational resources than its competitors. These assertions have not just sparked technical debate - they've triggered a seismic reaction in global technology markets.
The ripple effects of DeepSeek's emergence reverberated through the U.S. tech sector with unprecedented force, triggering what analysts characterize as one of the most significant single-day tech selloffs in recent memory. The immediate impact manifested in a staggering $1.2 trillion reduction in market capitalization, fundamentally challenging established assumptions about AI development costs and computational efficiency.

The scale of DeepSeek's operation becomes clear when examining their reported resource utilization:
2,048 Nvidia H800 GPUs
57-day training period
2.78 million GPU hours total consumption
For context, Meta's Llama 3 required approximately 30.8 million GPU hours. This stark difference has drawn intense scrutiny from the technical community, leading to deeper examination of DeepSeek's efficiency claims.
DeepSeek's widely-publicized $5.6 million development cost requires careful examination.
A quick analysis reveals several crucial factors absent from this figure:
Research Infrastructure:
Extensive prior research and development costs
Multiple iterations of architectural testing
Specialized development environments
Technical Requirements:
GPU cluster acquisition and maintenance
Custom optimization tools
Specialized cooling and power infrastructure
Human Capital:
Expert engineering teams
PTX-level optimization specialists
System architecture designers
The Open Source Shift
DeepSeek's decision to release its core models under the MIT license represents a significant challenge to the established proprietary model of AI development. This move stands in contrast to companies like Meta, whose Llama 3 maintains certain proprietary elements despite its partially open approach. The implications of this strategic choice run deep: by making their technology openly accessible, DeepSeek has effectively democratized access to efficient AI architectures while simultaneously inviting global scrutiny of their claims.
This open approach has already begun reshaping competitive dynamics within the AI sector. Traditional tech giants, accustomed to protecting their innovations through strict intellectual property controls, now face pressure to justify their closed development approaches. The availability of DeepSeek's architecture has accelerated the pace of innovation, as developers worldwide can build upon and optimize these foundations. However, this openness also carries risks - particularly in terms of potential misuse and security concerns.
GPU Demand and Market Evolution
While DeepSeek's efficiency claims initially suggested a potential decrease in GPU requirements, the reality has proven more complex. Despite architectural innovations promising reduced computational needs, overall semiconductor demand continues to show robust growth. Gartner and IDC's projections of 14-15% growth in semiconductor demand for 2025 reflect a market adapting to, rather than retreating from, intensive AI computation.

This apparent paradox reflects a fundamental shift in how the industry approaches computational efficiency. Rather than simply reducing overall GPU usage, the market is evolving toward more sophisticated optimization strategies, suggesting a future where computational efficiency comes not just from better algorithms but from more specialized hardware.
DeepSeek's approach to efficiency has also triggered a broader reassessment of AI development methodologies. Traditional assumptions about the relationship between model size and capability are being challenged, leading to new approaches in architectural design. This shift extends beyond simple optimization, pushing the industry toward fundamental innovations in how AI systems are constructed and trained.
The impact of these changes is particularly evident in how major tech companies are adapting their development strategies. The emphasis has shifted from raw computational power to architectural efficiency, with companies investing heavily in novel approaches to model design and training methodologies. This transformation suggests a future where AI development focuses not just on capability but on the elegant use of available resources.
A Pivotal Moment in AI Development
The emergence of DeepSeek is a pivotal moment in AI development, challenging fundamental assumptions about computational requirements and development costs. Through its innovative MoE architecture and selective parameter activation, the company has demonstrated that state-of-the-art AI capabilities might be achievable with significantly fewer resources than previously thought.
Yet DeepSeek's most lasting impact may stem from its open-source development. By releasing its core technologies under the MIT license, the company has initiated more democratization of AI innovation. As the industry adapts to all of these new dynamics, the focus is shifting from raw computational power to architectural efficiency, suggesting a future where AI development prioritizes elegant resource utilization over brute-force scaling. Whether DeepSeek's specific claims prove accurate, their emergence has already succeeded in pushing the industry toward a more critical examination of established practices.
Keep a lookout for the next edition of AI Uncovered!
Follow our social channels for more AI-related content: LinkedIn; Twitter (X); Bluesky; Threads; and Instagram.