


Customizing ChatGPT and Claude: Leveraging Enterprise Data Sources for Tailored AI Solutions
The key to effective customization lies in the strategic use of enterprise data sources.


Powerful large language models (LLMs) like OpenAI's ChatGPT and Anthropic's Claude, or AI agents and GPTs, offer impressive out-of-the-box capabilities, but many organizations are unaware that they can be customized to suit specific business needs and use cases. This customization process, often referred to as fine-tuning, allows companies to harness the power of existing LLMs while infusing them with domain-specific knowledge and aligning them with organizational goals.
The key to effective customization lies in the strategic use of enterprise data sources. By carefully selecting and preparing relevant data, companies can create AI assistants that not only understand their unique context but also communicate in a manner consistent with their brand voice and values. And the best part is that this can be a fairly simple process if you want it to be, and it can be adopted by businesses of all sizes.
Understanding the Data Spectrum for LLM Customization
To effectively customize an existing LLM for your organization, it's crucial to understand the types of data that can be leveraged. This understanding will help you create a comprehensive knowledge base that captures the nuances of your specific domain and use cases.
Structured vs. Unstructured Data
When customizing LLMs like ChatGPT or Claude, you can utilize both structured and unstructured data:
Structured Data: This includes information organized in a predefined manner, often in rows and columns, or in a database format where data is stored according to specific schemas. Structured data is organized, searchable, and readily accessible for processing. For instance, this type of data is common in spreadsheets, databases, and CRM systems where fields and categories are well-defined and consistent across records. While LLMs primarily work with text, structured data can be converted into a format they can understand. Examples relevant to LLM customization might include:
Product specifications converted to descriptive text, outlining specific features, dimensions, or compatibility.
Customer data summarized into profiles that detail purchase history, preferences, and demographic information.
Financial metrics with textual explanations of quarterly revenue, year-over-year growth, and customer acquisition costs.
Unstructured Data: This encompasses information that doesn’t conform to a specific data model, meaning it’s not neatly organized or standardized. Unstructured data is typically free-form and can include large volumes of natural language text, images, audio, and video. Because of its richness and variety, it provides extensive context and helps the LLM adapt to unique organizational nuances. Examples include:
Company blog posts and articles that represent the brand’s voice, tone, and public communication style.
Internal documentation and guidelines outlining operational standards, product knowledge, and workflows.
Transcripts of customer service calls, which capture real conversational exchanges, common questions, and responses.
Employee handbooks and training materials that provide insight into company culture, policies, and onboarding processes.
Unstructured data is especially powerful for customization as it provides rich context and language variety, helping the LLM understand and mimic your organization’s communication style.
Internal vs. External Sources
Another important distinction in the data spectrum is the origin of the information:
Internal Sources: These are proprietary data assets generated within your organization, often containing unique insights, processes, and language that define your company’s operations and culture. Internal sources are typically confidential and offer detailed, organization-specific information not found in public channels, making them essential for creating a truly customized LLM. They are crucial for tailoring an LLM to your specific needs. Examples include:
Company wikis and knowledge bases that house detailed procedural information, product documentation, and employee expertise.
Internal reports and presentations containing performance metrics, project updates, and executive insights specific to your organization.
Proprietary research findings, such as results from in-house R&D or customer feedback analyses, which offer competitive insights.
Brand guidelines and marketing materials to ensure the LLM captures the tone, style, and messaging unique to your brand.
External Sources: These encompass publicly available or licensed data relevant to your industry or use case. External sources provide valuable context on general knowledge, industry standards, and evolving trends, helping the LLM understand the broader landscape. They can help broaden the LLM’s understanding of your field. Examples include:
Industry publications and white papers that discuss current trends, challenges, and innovations relevant to your sector.
Relevant academic research papers offering foundational insights and advanced theories applicable to your domain.
Public datasets specific to your sector, such as government statistics, economic indicators, or social media analytics, which inform broader contextual understanding.
Licensed content from authoritative sources in your field, like news outlets, journals, or specialized databases, to ensure the LLM has a well-informed base of external knowledge.
Balancing internal and external sources is key to creating a well-rounded custom AI assistant. Internal data ensures the LLM reflects your organization’s specific knowledge and tone, while external data helps it understand broader industry contexts and general knowledge relevant to your field.
By understanding these aspects of the data spectrum, you can begin to identify and collect the most valuable information for customizing popular LLMs to your organization's needs.
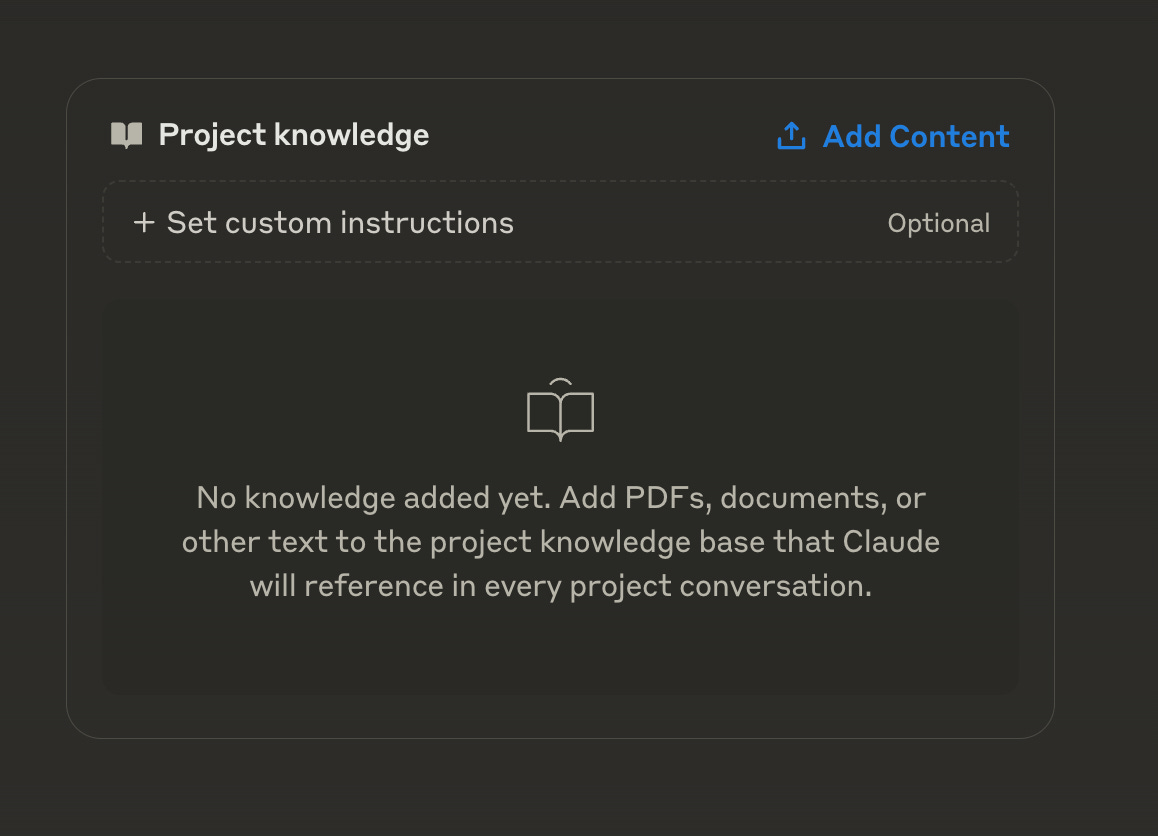
Key Categories of Enterprise Data for LLM Customization
When customizing LLMs like ChatGPT or Claude for your organization, certain types of enterprise data prove particularly valuable. These data categories can significantly enhance the model's understanding of your business context, industry-specific terminology, and operational procedures. Let's explore five crucial categories:
Proprietary Content Repositories
Proprietary content repositories are goldmines for LLM customization. These include:
Internal wikis and knowledge bases
Company blogs and newsletters
Product documentation and user manuals
Marketing materials and brand guidelines
By incorporating this data, you can ensure your customized AI assistant accurately represents your brand voice, product knowledge, and company-specific information. For example, a customized ChatGPT for a tech company could provide detailed, accurate information about their product lineup, drawing from internal product documentation.
Customer Interaction Logs
Customer interaction data is crucial for training AI models to handle customer queries effectively. Sources include:
Customer support ticket logs
Live chat transcripts
Email correspondence
Social media interactions
This data helps the LLM understand common customer issues, preferred solutions, and the appropriate tone for customer communication. A Claude chat, customized with this data could, for instance, more effectively handle customer inquiries, mimicking your best support agents' problem-solving approaches and communication styles.
Industry-Specific Datasets
To ensure your AI assistant is well-versed in your industry, consider incorporating:
Industry reports and white papers
Trade publications and journals
Market research data
Competitor analysis reports
This data broadens the model's understanding of your industry landscape, trends, and terminology. For example, a ChatGPT customized for a financial services firm could provide insights on market trends or explain complex financial products using industry-standard terminology.
Regulatory and Compliance Documents
For industries with strict regulatory requirements, including compliance-related data is crucial:
Industry regulations and standards
Company policies and procedures
Compliance training materials
Legal documents and contracts
This ensures your AI assistant can provide accurate, compliant information. A customized Claude for a healthcare organization, for instance, could offer guidance on HIPAA compliance or explain internal policies related to patient data handling.
Technical Documentation and Knowledge Bases
For organizations dealing with complex products or services, technical documentation is invaluable:
API documentation
System architecture diagrams
Troubleshooting guides
Internal development wikis
This data allows your AI assistant to handle technical queries with precision. A ChatGPT customized with this information could assist developers with API usage, explain system architectures, or guide IT staff through complex troubleshooting processes.
By strategically incorporating these categories of enterprise data, you can create a highly specialized version of ChatGPT, Claude, or other LLMs that not only speaks your company's language but also embodies its collective knowledge and expertise. This customized AI assistant can become a powerful tool for internal knowledge management, customer support, and even specialized task completion within your organization.
Remember, the key to effective customization lies not just in having these data sources, but in curating them carefully to ensure quality, relevance, and alignment with your specific use cases.
Leveraging External Data Sources
While internal data is crucial for customizing LLMs to your organization's specific needs, external data sources can significantly enhance the model's overall knowledge and capabilities. Here are key external sources to consider when tailoring ChatGPT, Claude, or similar LLMs:
Academic and Research Papers
Academic literature can provide cutting-edge insights and deep domain knowledge:
Peer-reviewed journal articles in your field
Conference proceedings and presentations
Dissertations and theses
For example, a ChatGPT instance customized for a biotech company could incorporate recent research papers, enabling it to discuss the latest advancements in genetic engineering or drug discovery.
Open-Source Datasets
Open-source datasets can broaden your AI assistant's knowledge base:
Government data portals (e.g., data.gov)
Industry-specific open datasets
Kaggle datasets relevant to your field
A Claude instance tailored for a smart city project could utilize open datasets on urban planning, traffic patterns, and energy consumption to provide more informed analyses and recommendations.
Public Domain Literature
Public domain works can enrich your AI's language model and general knowledge:
Classic literature and historical texts
Government publications and reports
Expired patents related to your industry
This data can be particularly useful for companies in creative industries or those dealing with historical contexts. A customized ChatGPT for a publishing house, for instance, could draw on classic literature to better understand narrative structures or literary devices.
Licensed Third-Party Content
When open-source options are limited, licensed content can fill crucial knowledge gaps:
Industry reports from research firms
Specialized databases (e.g., legal, medical, financial)
Premium news services and trade publications
For example, a Claude instance customized for a law firm could incorporate licensed legal databases, enabling it to provide more accurate and up-to-date legal information.
Strategies for Data Curation and Preparation
Once you've identified your data sources, proper curation and preparation are crucial to ensure your customized LLM performs optimally. Here are key strategies to consider:
Quality Assessment and Cleaning
Data Validation: Verify the accuracy and relevance of your data. Remove outdated or irrelevant information that could confuse the model.
Formatting Consistency: Ensure consistent formatting across your dataset. This might involve standardizing date formats, units of measurement, or industry-specific terminology.
Deduplication: Remove redundant data to prevent the model from overemphasizing certain information.
For instance, when customizing ChatGPT with customer interaction logs, you might clean the data by removing personally identifiable information, standardizing product names, and eliminating duplicate entries.
Bias Detection and Mitigation
Diverse Representation: Ensure your dataset represents a wide range of perspectives, avoiding over-representation of any particular group or viewpoint.
Bias Auditing: Use bias detection tools to identify potential biases in your dataset. This could involve analyzing the distribution of demographic attributes or sentiment across your data.
Balanced Augmentation: If biases are detected, consider augmenting your dataset with additional data to create a more balanced representation.
For example, when customizing Claude for a global company, you might audit your dataset to ensure it includes diverse cultural perspectives and augment it with region-specific data where gaps are identified.
Data Augmentation Techniques
Paraphrasing: Generate multiple versions of key information using different wordings. This can help the model understand concepts rather than memorizing specific phrasings.
Translation and Back-Translation: For multilingual organizations, translate content into different languages and back to the original. This can help the model better understand semantic meanings across languages.
Synthetic Data Generation: Use AI techniques to generate additional, synthetic data points based on your existing data. This can be particularly useful for expanding limited datasets.
When customizing ChatGPT for a customer service application, you might use paraphrasing to create multiple versions of common customer queries, helping the model recognize the same question asked in different ways.
By carefully curating and preparing your data using these strategies, you can significantly enhance the performance and reliability of your customized LLM. Remember, the quality of your input data directly impacts the quality of your AI assistant's outputs.
Of course, LLMs themselves can be used to assist in these very tasks!
Measuring the Impact of Data Sources on LLM Performance
After customizing an LLM like ChatGPT or Claude with your enterprise data, it's crucial to measure the impact of these modifications. This evaluation helps ensure that your AI assistant is performing as expected and delivering value to your organization. Let's explore key performance indicators (KPIs) and testing strategies to assess your customized LLM's effectiveness.
Key Performance Indicators for Customized LLMs
When evaluating the performance of your tailored AI assistant, consider the following KPIs:
Accuracy: Measure how often the model provides correct and relevant information. This is particularly important for domain-specific knowledge.
Example: For a legal AI assistant, track the percentage of correctly cited legal statutes or case law.
Measurement: To measure accuracy for a customized LLM, periodically sample interactions and have domain experts review responses for correctness, scoring each as correct or incorrect. Calculate the accuracy percentage by dividing correct responses by total responses sampled, then compare against a set benchmark to track improvements over time.
Relevance: Assess how well the model's responses align with the specific context of your business.
Example: For a customer service AI, evaluate whether responses incorporate company-specific policies and procedures.
Measure: To measure relevance, regularly sample responses and have reviewers check if they align with company-specific context, such as incorporating relevant policies and procedures. Score each response as relevant or irrelevant, then calculate the relevance percentage by dividing relevant responses by total sampled responses. This metric helps gauge how well the AI adheres to your business’s specific requirements.
Consistency: Check if the model maintains a consistent tone and adheres to your brand voice across various interactions.
Example: Ensure that a sales-oriented AI consistently uses approved marketing language and value propositions.
Measure: Develop a rubric that defines key elements of your brand voice (e.g., tone, key phrases, prohibited language). Randomly sample AI responses and rate them on a scale (e.g., 1-5) for each element. Calculate an average consistency score across samples and track this over time to ensure the AI maintains brand alignment.
Efficiency: Measure improvements in task completion time or reduction in human intervention needed.
Example: Track the reduction in time taken to draft initial responses to customer inquiries.
Measurement: Compare the average time taken for the AI to complete tasks versus human operators. For instance, in customer service, measure the average response time for AI-generated initial drafts compared to human-written ones. Also, track the percentage of AI responses that require human editing or intervention.
User Satisfaction: Gather feedback from end-users on their experience with the customized AI assistant.
Example: Conduct surveys or analyze user ratings for interactions with the AI in customer support scenarios.
Measurement: Implement a post-interaction survey asking users to rate their satisfaction on a scale (e.g., 1-5 stars). Calculate the average satisfaction score and track it over time. Additionally, use sentiment analysis on user comments to gauge positive, neutral, or negative reactions to AI interactions.
Domain-Specific Metrics: Develop KPIs tailored to your industry or use case.
Example: For a healthcare AI, track its accuracy in suggesting appropriate ICD-10 codes for medical conditions.
Measurement: For the healthcare example, have medical coders review a sample of AI-suggested ICD-10 codes. Calculate the percentage of correctly suggested codes. For other industries, identify critical domain-specific tasks and develop similar accuracy or efficiency metrics.
Error Rate: Monitor the frequency of incorrect or inappropriate responses.
Example: Track instances where the AI provides outdated information or misinterprets industry-specific terminology.
Measurement: Implement a flagging system where users or reviewers can mark AI responses as errors. Calculate the error rate by dividing the number of flagged responses by the total number of interactions over a given period. Categorize errors (e.g., factual, contextual, language) to identify areas for improvement.
Hallucination Rate: Assess how often the model generates false or unsupported information, especially critical for maintaining trust and compliance.
Example: In a financial services context, monitor for instances where the AI invents non-existent financial products or regulations.
Measurement: Conduct regular audits where domain experts review a sample of AI responses, specifically looking for invented or unsupported information. Calculate the hallucination rate by dividing the number of responses containing hallucinations by the total number of sampled responses. Track this rate over time and after each model update or data refresh.
The Bottom Line
Customizing popular Large Language Models like ChatGPT and Claude offers a powerful opportunity for enterprises to harness AI technology tailored to their unique needs. By strategically leveraging diverse data sources—from proprietary content repositories to customer interaction logs and industry-specific datasets—organizations can create AI assistants that not only understand their specific context but also communicate in alignment with their brand voice and values.
The key to success lies in careful data curation, rigorous testing, and continuous performance measurement. As we've explored, this process involves identifying relevant data categories, implementing effective preparation strategies, and utilizing KPIs and A/B testing to refine the model's outputs. By embracing this approach, businesses can transform general-purpose LLMs into specialized tools that drive efficiency, enhance decision-making, and provide personalized experiences across various operational areas.
In our next edition, I will show you exactly how anyone can upload and create custom knowledge bases in both Claude and ChatGPT.
Keep a lookout for the next edition of AI Uncovered!
Follow on Twitter, LinkedIn, and Instagram for more AI-related content.